Üretken yapay zeka araçları sıklıkla az popüler veya alışılmadık kaynaklara gözatıyor
Gönderilme zamanı: 30 Eki 2025, 22:09

Araştırmacılar, yapay zekanın Google'ın en iyi bağlantılarından değil, internetin kenarlarından arama yaptığını buldu
Bulgular, üretken yapay zekanın arama mimarisini nasıl dönüştürdüğüne dair erken bir ampirik anlık görüntü sunuyor. Geleneksel arama motorları popülerlik ve sıralamaya bağlı kalırken, yapay zeka sistemleri senteze dayalı bir model oluşturuyor; bu da geri çağırma ile yorumlama arasındaki çizgiyi bulanıklaştırıyor.
Geleneksel web arama sonuçlarını yapay zeka destekli sistemler tarafından üretilen sonuçlarla karşılaştıran yeni bir akademik çalışma, üretken yapay zeka araçlarının sıklıkla daha az popüler veya alışılmadık kaynaklara dayandığını ortaya koydu. Bulgular, geleneksel arama motorları ile büyük dil modeline dayalı sistemlerin çevrimiçi bilgileri toplama ve sunma biçimleri arasındaki giderek artan uçurumu vurguluyor.
Bochum Ruhr Üniversitesi ve Max Planck Yazılım Sistemleri Enstitüsü'nden araştırmacılar, "Üretken Yapay Zeka Çağında Web Aramasının Karakterizasyonu" başlıklı bir ön baskı makalesi olarak yayınlanan analizi gerçekleştirdi . Çalışmada, Google'ın Yapay Zeka Genel Bakışları, Gemini-2.5 Flash ve OpenAI'nin GPT-4o'sunun iki çeşidi olan yerleşik web arama modu ve yalnızca modelin dış verilere ihtiyaç duyduğunu belirlediğinde web'e erişen GPT-4o Arama Aracı da dahil olmak üzere bir dizi yapay zeka tabanlı arama motorundaki farklılıklar ölçüldü.
Arama motorları, onlarca yıldır sayfaları indeksleyip sıralayarak, öncelikli olarak alaka düzeyine ve yetkinliğe göre sıralanmış bağlantı listeleri döndürerek faaliyet gösteriyordu. Buna karşılık, üretken yapay zeka sistemleri, birden fazla kaynaktan gelen bilgileri özlü ve özetlenmiş yanıtlar halinde sentezliyor. Araştırmacılar, bu değişimin bu yanıtları bilgilendiren web sitesi türlerini nasıl etkilediğini ölçmeyi amaçlıyordu.
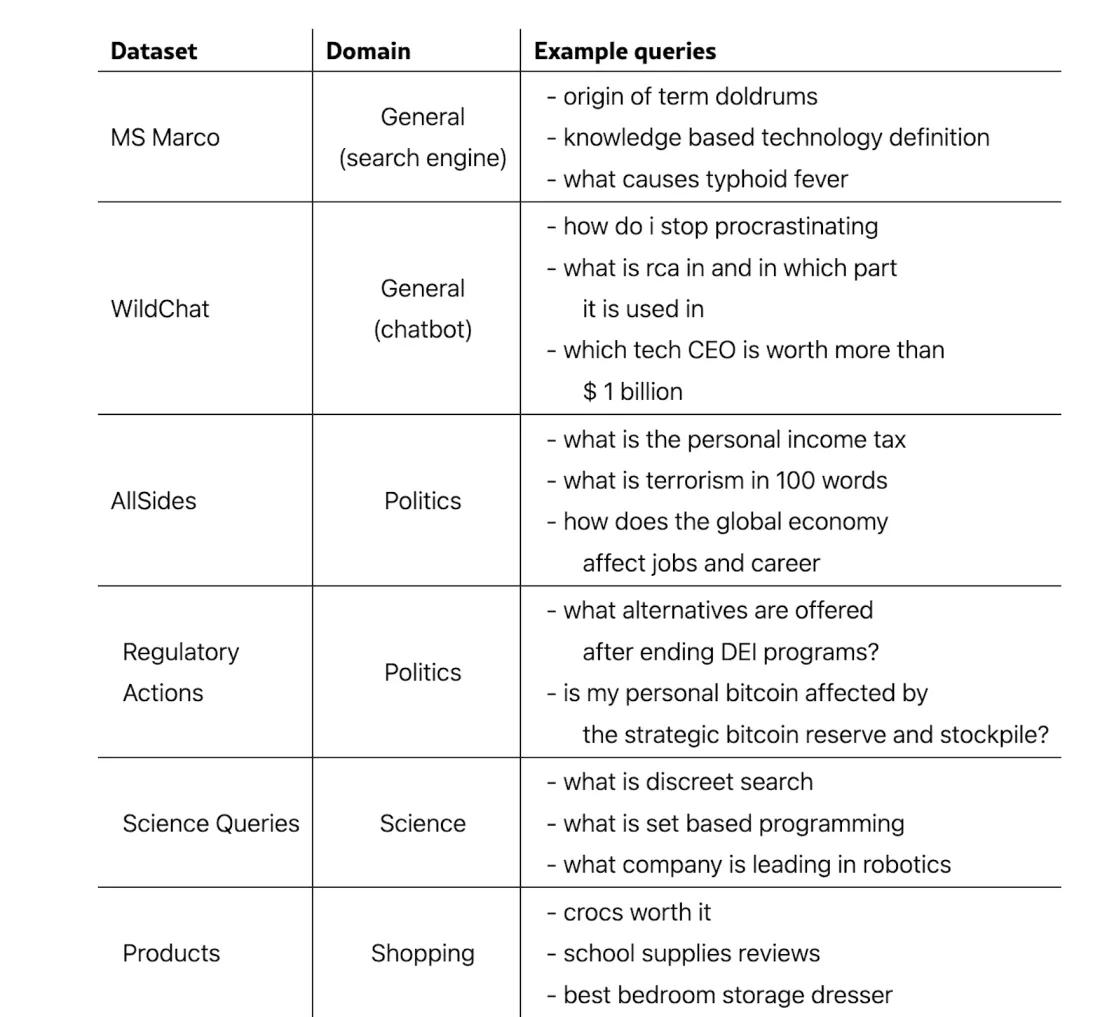
Hipotezlerini test etmek için, çeşitli herkese açık veri kümelerinden binlerce örnek sorgu oluşturdular. Bunlar arasında, WildChat veri kümesindeki ChatGPT etkileşimlerinden toplanan sorular, medya yanlılığı izleme sitesi AllSides tarafından kataloglanan genel sosyal ve politik konular ve Amazon'un ürün sıralama listesindeki en çok aranan 100 ürün yer alıyordu. Google'ın arama trendi verilerinden trend olan konular da karşılaştırmalı test için dahil edildi.
Her sorgu hem geleneksel Google Arama'ya hem de yapay zeka tabanlı sistemlere gönderildi. Araştırmacılar daha sonra yapay zeka tarafından oluşturulan yanıtlarda belirtilen alan adlarını, standart bir Google sonuç sayfasının ilk 10 ve ilk 100 bağlantısında görünen alan adlarıyla karşılaştırdı.
Farklar çarpıcıydı. Web alan adlarını popülerliğe göre sıralayan bağımsız bir izleme aracı olan Tranco'yu kullanan çalışma, yapay zeka tarafından oluşturulan arama sonuçlarının sürekli olarak en çok ziyaret edilen kategorilerin dışındaki web sitelerinden geldiğini ortaya koydu. Google'ın kendi Yapay Zeka Genel Bakış raporunda, alıntılanan kaynakların yarısından fazlası aynı sorgu için ilk 10 organik Google sonucunda yer almıyordu ve yüzde 40'ı ilk 100 bağlantıda bile yer almıyordu.
Gemini arama sonuçları da benzer bir örüntü gösterdi ve sıklıkla Tranco'nun ilk 1.000'i dışındaki alan adlarına atıfta bulundu. Araştırmacılar, Gemini tarafından atıfta bulunulan tipik veya "ortanca" kaynağın, yaygın olarak ziyaret edilen web sitelerinin eşiğinin altında kaldığını belirtti. GPT-4o ve web tabanlı muadili de daha az bilinen kaynaklardan yararlandı, ancak sosyal medya veya tartışma forumları yerine şirket sayfaları ve ansiklopediler gibi kurumsal alan adlarına atıfta bulunma eğilimindeydiler.
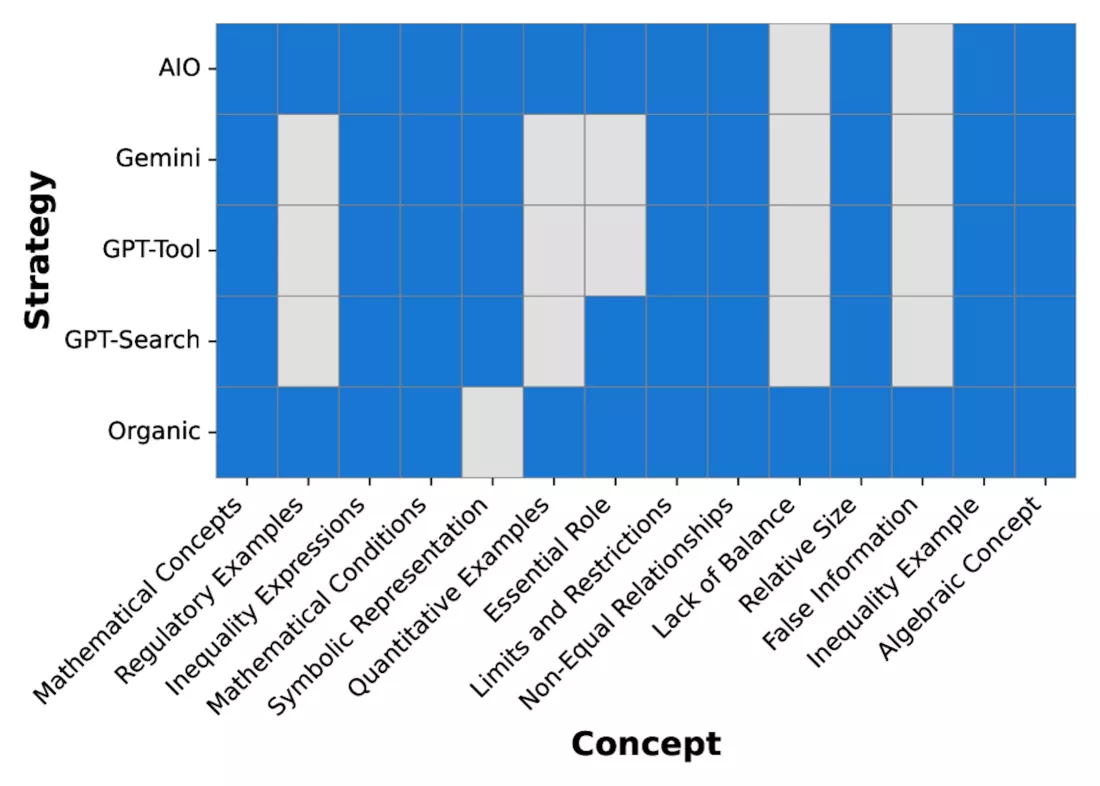
Çalışma, yapay zeka arama sonuçlarının daha düşük kalitede olduğu sonucuna varmadı; aksine, bilgi edinimine farklı bir yaklaşımı yansıttığı sonucuna vardı. Stanford Üniversitesi, LLOOM tarafından geliştirilen bağımsız bir değerlendirme aracı kullanan ekip, yapay zeka arama sistemlerinin geleneksel bir aramadaki ilk 10 bağlantıyla karşılaştırılabilir sayıda farklı kavramı kapsadığını tespit etti. Bu, yapay zeka yanıtlarının benzer bilgi genişliklerini özetlemesine rağmen, bazen bu verileri sıkıştırarak geleneksel arama sonuçlarında korunan nüansları küçümsediğini gösteriyor.
Bu etki, özellikle birden fazla kişi tarafından paylaşılan isimler gibi belirsiz arama terimleri için belirgindi. Standart bağlantı tabanlı arama, daha geniş bir bağlamsal kapsam sağlama eğilimindeyken, yapay zeka yanıtları genellikle bu durumları tek bir yorumda birleştirerek bazı alternatif sonuçları göz ardı ediyordu.
Üretken sistemler, büyük dil modellerinin önceden eğitilmiş bilgisinden yararlanarak arka plan bağlamını sentezlemede avantaj sağladı. Örneğin, Arama Aracı ile GPT-4o, bazen herhangi bir harici veriye atıfta bulunmadan kapsamlı özetler sundu ve tamamen modelin dahili bilgi tabanına güvendi. Bu davranış, köklü konular için faydalı oldu, ancak güncel olaylar veya son dakika haberleri için daha az güvenilirdi.
Eylül ortasından itibaren popüler Google sorgularıyla test edildiğinde, GPT-4o'nun web tabanlı sürümü güncel bilgileri almada sıklıkla başarısız oldu ve açıklama talepleri veya belirsizliğin basitçe kabul edilmesi gibi geçici yanıtlar üretti. Bu durum, sistemin açıkça gerekli olmadıkça harici kaynaklara erişim konusundaki isteksizliğini yansıtıyordu.
Yazarlar, üretken yapay zeka aramasının doğruluğunu veya kalitesini değerlendirmenin yeni ölçütler gerektirdiğini vurguladılar. Gelecekteki araştırmalarda, özellikle kaynak çeşitliliğini, kavramsal kapsam aralığını ve yapay zeka sistemlerinin bilgileri tutarlı özetlere dönüştürmedeki etkinliğini hesaba katan çerçeveler olmak üzere, geleneksel arama sıralaması için tasarlananların ötesinde ölçütlerin kullanılması çağrısında bulundular.
Kaynak :
https://www.techspot.com/news/110039-re ... s-not.html