Google Gemini, reklamında söylendiği kadar iyi değil
Gönderilme zamanı: 03 Tem 2024, 12:45

Üretken AI'nın iyi olması gereken bir şey varsa, o da yazılı sözcükleri analiz etmektir. Ancak iki çalışma, bu yeteneğin abartılmış olabileceğini öne sürüyor. Bir çalışma, Gen AI'nın uzun biçimli kitapları anlamakta zorluk çektiğini gösterirken, bir diğeri bu modellerin videolarla ilgili soruları yanıtlamayı zor bulduğunu gösteriyor. Bu, şirketlerin iş gücünü Gen AI ile zenginleştirirken dikkate alması gereken bir şey.
Üretken AI her türden yaratıcının yüreğine korku saldı, ancak özellikle yazılı sözcüklerle uğraşanların yüreğine. Metin yazarları için serbest çalışma, büyük ölçüde son aylarda ortaya çıkan GenAI motorlarının sayısından dolayı kurudu. AI'nın başlangıçtaki abartısını tam olarak karşılamadığının giderek daha fazla farkına varılmasına rağmen, diğer gig çalışma biçimleri de etkilendi.
İki yeni çalışma, bu sohbet robotlarının bazı sınırlamalarını göstererek, daha önce fark edilenden daha kapsamlı olabileceklerini ortaya koyuyor. Her iki çalışma da GenAI'nin muazzam miktardaki verileri ne kadar iyi anlamlandırabildiğini inceliyor. Özellikle, biri AI dil modellerinin uzun hikayeleri anlama ve devam ettirme yeteneğini test ederek , bu modellerin tipik kısa menzilli işlemenin ötesinde genişletilmiş hikayeleri ne kadar iyi kavrayabildiğini ve üzerine inşa edebildiğini değerlendirdi.
Diğer çalışma, görme dili modellerinin performansını değerlendirmeye odaklandı . Her iki çalışma da yapay zekanın, satış noktaları olarak büyük miktarda veriyi işleme ve analiz etme yeteneklerini vurgulayan Google'ın en son Gemini üretken yapay zeka modelleri de dahil olmak üzere yetersiz kaldığını buldu.Araştırmacılar, 520 sayfalık bir kitap için Gemini 1.5 Pro'nun doğru/yanlış ifadelerine %46,7 oranında doğru cevap verdiğini, Gemini Flash'ın ise yalnızca %20 oranında doğru cevap verdiğini buldu.
Örneğin, Google'a göre Gemini 1.5 Flash bir saatlik videoyu, 11 saatlik sesi veya 700.000'den fazla kelimeyi tek bir sorguda analiz edebilir. Gazetecilere yaptığı bir sunumda Google, 14 dakikalık bir videoyu bir dakikada nasıl analiz edebileceğini gösterdi. Ancak UMass Amherst'te doktora sonrası araştırmacı ve çalışmalardan birinin ortak yazarı olan Marzena Karpinska'ya göre , bağlamı kavraması -en azından uzun biçimli yazılı bağlamı- şüpheli. "Gemini 1.5 Pro gibi modeller teknik olarak uzun bağlamları işleyebilirken, modellerin içeriği gerçekten 'anlamadığını' gösteren birçok vaka gördük."
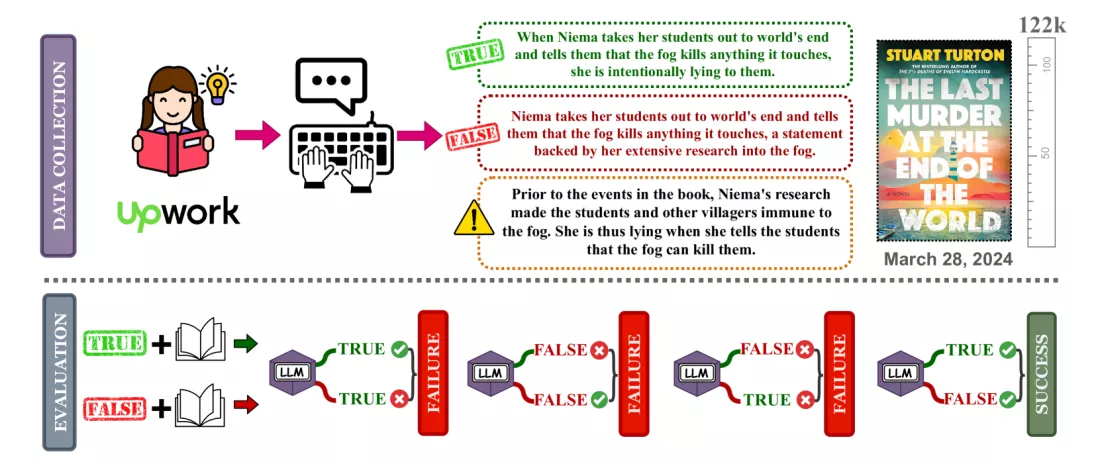
Karpinska, Allen Yapay Zeka Enstitüsü ve Princeton'dan araştırmacılarla birlikte, modellerden son kurgu kitaplar hakkındaki doğru/yanlış ifadeleri değerlendirmelerini istedi; onlara belirli ayrıntılar ve olay örgüsü noktaları hakkında sorular sordu.
Araştırmacılar, 260.000 kelime veya 520 sayfalık bir kitap için Gemini 1.5 Pro'nun doğru/yanlış ifadelerine %46,7 oranında doğru cevap verdiğini, Gemini Flash'ın ise yalnızca %20 oranında doğru cevap verdiğini buldu.
GPT-4, NoCha (Novel Challenge) veri setinde %55,8 ile en yüksek doğruluğa ulaştı. Çalışma ayrıca, kararları için model tarafından oluşturulan açıklamaların, doğru etiketlenmiş iddialar için bile sıklıkla yanlış olduğunu buldu.
"Modellerin, cümle düzeyindeki kanıtları alarak çözülebilen iddialara kıyasla, kitabın daha büyük bölümlerini veya hatta tüm kitabı dikkate almayı gerektiren iddiaları doğrulamakta daha fazla zorluk çektiğini fark ettik," dedi Karpinska. "Nitel olarak, modellerin, bir insan okuyucu için açık olan ancak metinde açıkça belirtilmeyen örtük bilgiler hakkındaki iddiaları doğrulamakta da zorluk çektiğini gözlemledik."

İkinci çalışmada araştırmacılar, matematiksel akıl yürütme, görsel soru cevaplama (VQA) ve karakter tanıma gibi çeşitli görevlerde, çeşitli VLM'lerin görsel bağlam uzunluğu arttıkça zorluk çektiğini buldular. Genel olarak, mevcut son teknoloji VLM'ler uzun görsel bağlamlarda soruları cevaplarken alakasız bilgileri görmezden gelmekte zorluk çekiyor.
Ortak yazarlar, doğum günü pastası fotoğrafı gibi bir görüntü veri kümesi oluşturdular ve modelin görüntülerde tasvir edilen nesneler hakkında cevaplaması gereken sorularla eşleştirdiler. Görüntülerden birini rastgele seçtiler ve slayt gösterisi benzeri görüntüler oluşturmak için öncesine ve sonrasına "dikkat dağıtıcı" görüntüler eklediler.
"Görsellerle ilgili gerçek soru-cevap görevlerinde, test ettiğimiz tüm modeller için özellikle zor görünüyor," diyor UC Santa Barbara'da doktora öğrencisi ve çalışmanın ortak yazarlarından biri olan Michael Saxon. "Bu küçük miktardaki akıl yürütme - bir sayının bir çerçevede olduğunu fark etmek ve onu okumak - modeli bozan şey olabilir."
Gemini Flash burada da 25 resimden oluşan bir slayt gösterisinden el yazısıyla yazılmış altı rakamı yazıya dökmesi istendiğinde iyi bir performans gösteremedi; yazıya dökmelerin yaklaşık %50'sini doğru yaptı ve sekiz rakamlı yazılarda ise %30'unu doğru yaptı.
Kaynak :
https://www.techspot.com/news/103610-go ... er-ai.html?